

Как и почему образуются пробки на дорогах
Математические модели для анализа транспортных потоков
Моделирование транспортных потоков — хороший пример междисциплинарного исследования. Основные вопросы для исследования звучат довольно просто. Как и почему образуются пробки (заторы)? Как формируется картина загрузки улиц, которую мы видим в «Яндекс.Пробки»? Что такое равновесное распределение водителей по маршрутам (путям)? Как определить, сколько водителей хотят проехать из одного района в другой, то есть как формируются корреспонденции? Как корреспонденции влияют на равновесие?

Фото: Коммерсантъ / Александр Казаков / купить фото
Для математического ответа на эти и многие другие вопросы привлекаются различные разделы современной теории игр — в частности, популяционные игры загрузки и теории макросистем, рассматривающие эргодические марковские процессы и явление концентрации меры. Ниже на простых примерах мы постараемся ответить на эти вопросы и объяснить основные механизмы формирования равновесных конфигураций в транспортных сетях, привлекая внимание к более естественным, на наш взгляд, подходам, чем те, которые в настоящее время широко используются на практике.
Как образуются пробки
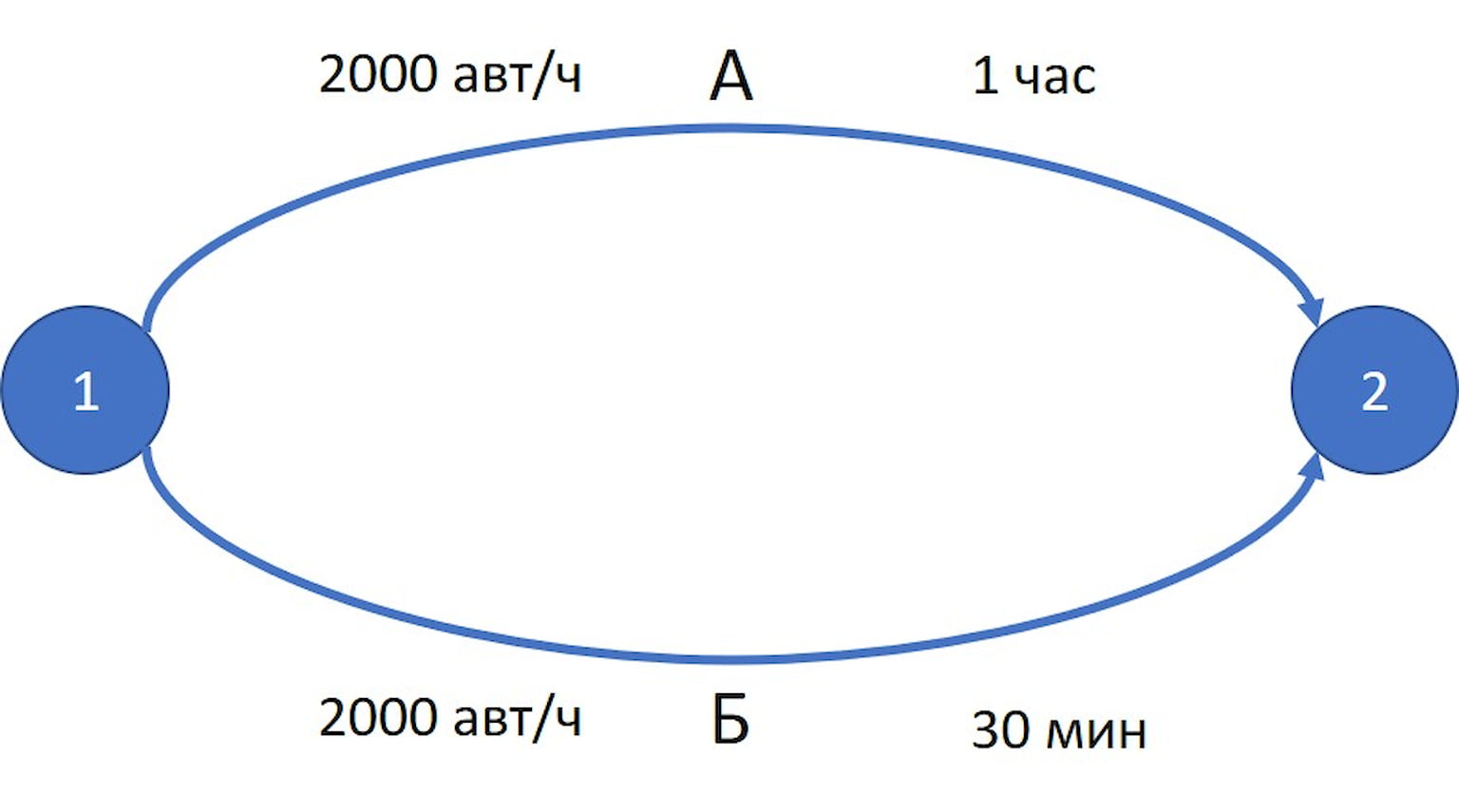
Начнем c первого вопроса: как образуются пробки? Следуя Ю. Е. Нестерову (российский ученый, работающий сейчас в Бельгии, один из самых известных специалистов в мире в области численных методов оптимизации, лауреат премий Данцига и фон Неймана; описываемый далее подход был предложен им совместно с А. Де Пальмой в 2000 году), рассмотрим следующий пример. Пусть есть два района 1 и 2, которые соединены двумя дорогами A и Б. При этом максимальная пропускная способность каждой дороги 2 тыс. автомобилей в час. При потоке меньше максимального время движения по дороге A — 1 час, а по дороге Б — 30 минут. Если же поток равен максимальному, то время проезда может быть любым (зависит от размеров пробки на дороге), но не меньше времени свободного проезда. Чтобы понять, как образуется пробка, будем постепенно увеличивать поток автомобилей из района 1 в район 2, то есть число автомобилей, которое хочет переместиться из района 1 в район 2 за один час. При маленьком потоке обе дороги не будут загружены и водители, стремясь уменьшить свои временные затраты, будут выбирать маршрут, проходящий по дороге Б. С увеличением потока из района 1, когда на дороге Б будет достаточно много водителей, из-за ограничения на пропускную способность на дороге Б начнет скапливаться пробка. Например, если на въезде в район 2 в конце дороги Б имеется светофор, на котором будет происходить рост пробки. Пробка будет расти до тех пор, пока водители не начнут терять в ней 30 минут. Тогда суммарные потери на каждой из двух дорог сравняются и водители, выезжающие из района 1, начнут использовать дорогу А.
Как распределить водителей по дороге
Рассмотрим теперь вопрос равновесного распределения водителей по маршрутам. Для этого предположим, что поток из района 1 в район 2 составляет 3 тыс. машин в час. Поскольку пропускная способность дороги Б составляет 2 тыс. машин в час, то по ней и едет не больше 2 тыс. машин в час. Если по ней будет ехать меньше 2 тыс. машин в час, то водители, выбирающие, проехать ли им по дороге Б за 30 минут или по дороге А за 1 час, выберут дорогу Б, тем самым увеличив поток на дороге Б. Если же по дороге Б едет ровно 2 тыс. автомобилей в час и они тратят на проезд 1 час из-за пробки, а оставшиеся 1 тыс. машин в час едут по свободной дороге А и тоже тратят на проезд 1 час, то система будет находиться в равновесии. Водителям будет невыгодно отклоняться от выбранного маршрута, так как это повлечет увеличение суммарных затрат. Такая ситуация, когда невыгодно отклоняться от выбранной стратегии (в данном случае стратегия — это выбор маршрута для проезда), называется равновесием по Нэшу.
Рассмотренная ситуация является ситуацией, когда эгоистически (рационально) настроенные агенты пользуются общим ресурсом. Без вмешательства регулятора это может приводить к неоптимальности системы в целом. Так, если бы по дороге А проезжала 1001 машина в час, а по дороге Б — 1999, то для водителей, едущих по дороге А, ничего бы не изменилось в смысле затрат. А вот водители, использующие дорогу Б, добирались бы в два раза быстрее. Таким образом, равновесие по Нэшу может быть неэффективно по Парето.
Отметим, что этот пример не только удачно показывает, что такое равновесие в транспортной сети, но и демонстрирует важный факт: понятие «равновесие» вовсе не означает (социальный) оптимум.
Пожалуй, самым известным примером этого наблюдения является игра «дилемма заключенного», неоднократно обыгрываемая в совершенно разных контекстах (политика, биология и т. д.; см., например, Р. Докинз «Эгоистичный ген»). Механизм борьбы с такими «эгоистичными» равновесиями — штрафы. Конкретно в данном примере можно взимать плату за проезд с дороги Б в размере стоимости 30 минут времени водителей.
На основе описанного выше принципа можно сформировать задачу линейного программирования (с числом переменных, равным числу ребер транспортного графа, и аналогичным числом ограничений), решение которой будет давать искомое равновесие в общем случае. Вычислительно получаемая таким образом задача оказывается не такой уж и сложной задачей даже для мегаполисов. Да и в плане данных, все, что требуется знать, это два числа по каждому ребру (участку дороги): пропускная способность и время свободного прохождения дороги (при разрешенной на этом участке скорости). Вся эта информация, как правило, выделяется из графа транспортной сети, полосности дорог и информации о светофорах. Также нужна матрица корреспонденций — информация о том, откуда, сколько и куда людей направляются в единицу времени.
Какие модели используются
В подавляющем большинстве пакетов транспортного моделирования используется модель, предложенная в 1956 году Beckmann, McGuire, Winsten, которую в литературе называют модель BMW, или модель Бекмана (см., например, Гасников А. В. и др.). В основе лежит тот же принцип поиска равновесия Нэша—Вардропа: каждый водитель выбирает для себя маршрут с наименьшими затратами, и равновесная конфигурация определяется таким распределением водителей по маршрутам, при котором никому не выгодно отклоняться от своего маршрута. Поиск равновесия сводится к решению задачи минимизации выпуклой функции, зависящей от затрат агентов на проезд по ребрам транспортной сети. Отличие от модели стабильной динамики состоит в том, что постулируется зависимость затрат времени на проезд по ребру от величины потока автомобилей на этом ребре.
Для определения этой зависимости используется простая физическая модель Танака, отражающая желание водителей, с одной стороны, двигаться как можно быстрее, а с другой стороны — безопасно. Возникает понятие безопасного расстояния между автомобилями как функции от их скорости в потоке. Расстояние в 2 м будет безопасным в пробке при движении со скоростью 5 км/ч, но не будет безопасным при движении со скоростью 100 км/ч. А именно, безопасное расстояние складывается из длины автомобиля, произведения времени реакции водителя на скорость автомобиля (это расстояние водитель пройдет, пока сообразит, что надо, например, затормозить) и слагаемого, пропорционального квадрату скорости. Квадрат скорости объясняется длиной тормозного пути (расстояние, которое проходит машина после торможения), определяемого, в свою очередь, переходом кинетической энергии в тепло за счет работы силы трения. Таким образом, у нас есть зависимость безопасного расстояния от скорости (1). Но безопасное расстояние есть величина обратная к плотности автомобилей (2). А скорость — это величина обратная к времени прохождения данного ребра (участка дороги) (3). В свою очередь, величина потока автомобилей (число автомобилей, проходящих в единицу времени через заданное сечение дороги) может быть вычислена как произведение скорости автомобилей (в потоке) на плотность (4). Таким образом, у нас есть пять величин: безопасное расстояние, плотность, скорость, поток, время и четыре соотношения между этими величинами, из которых можно найти искомую связь между временем прохождения ребра и потоком на ребре.
На практике используют упрощенную версию этой модели, называемую BPR-моделью. В наших исследованиях удалось показать, что эту функцию затрат можно параметризовать с помощью одного параметра так, что при стремлении этого параметра к нулю модель Бекмана переходит в модель стабильной динамики. На наш взгляд, модель стабильной динамики более адекватно отражает реальное поведение водителей, поскольку исходит из более простой входной информации.
***
В первой части мы постулировали, что корреспонденции известны. Но откуда они известны? Можно, конечно, их просто замерять, например, проводя опросы случайных респондентов. Однако по прошествии времени корреспонденции меняются, и хотелось бы знать модель, описывающую эти изменения.
Старые и новые модели
Первые такие модели (гравитационные, энтропийные) стали появляться в 60-е годы прошлого века (А. Дж. Вильсон «Энтропийные методы моделирования сложных систем»). Общая идея, заложенная в такие модели, довольно простая: люди стремятся работать ближе к месту жительства. Матрица корреспонденций зависит от того, сколько в каком районе мест жительства, рабочих мест и матрицы затрат (матрица стоимостей перемещений из одного района в другой). Совсем в вырожденном варианте модель расчета матрицы корреспонденций сводится к решению классической транспортной задачи линейного программирования (Толстой—Канторович—Гавурин) об организации наилучшей доставки товаров (водителей) из пунктов производства (мест жительства) в пункты потребления (рабочие места) с наименьшими суммарными затратами. Здесь, так же как и в части 1, при распределении водителей по путям каждый пользователь сети (в медленном масштабе времени) старается менять что-то в своей жизни так, чтобы ему стало лучше (например, быстрее добираться из дома на работу). И если бы все обладали абсолютно точной информацией о том, где какие есть условия для работы и для жизни, а также обладали бы возможностью часто менять жилье/работу, то мы и правда бы приближались в идеале к необходимости решать транспортную задачу, чтобы найти корреспонденции.
На практике же в такую идеализированную модель необходимо вносить поправки, связанные с ограниченной информированностью людей. А именно, считается, что каждый житель города имеет разную зашумленную информацию о том, где и какие условия (в модели распределения водителей по путям мы считали, что водители обладали точной информацией о том, какие затраты они будут нести, выбирая тот или иной маршрут; благодаря таким сервисам, как «Яндекс.Пробки», такое предположение, по-видимому, недалеко от истины). По каждому из потенциальных районов, куда он мог бы переехать жить/работать, он обладает набором «мнений» (знакомых, собранных из интернета и т. д.). Считается, что все эти мнения сформированы как настоящая оценка плюс случайный шум с некоторой дисперсией, которую мы обозначим через T^2. Собрав разные мнения по одному и тому же району, житель ориентируется на наиболее критичные мнения (это в разной степени свойственно многим людям; другими словами, многие люди при оценке исходят из наихудших прогнозов, желая, таким образом, обезопасить себя в случае их реализации). За счет наличия шума в собираемых оценках каждый житель уже с ненулевой вероятностью (зависящей от T) может выбрать неоптимальный для себя район для жизни/работы. Все это в действительности приводит к тому, что равновесие в такой модели (теперь оно уже называется стохастическое равновесие Нэша, в литературе по теории игр также можно встретить название квантильное равновесие, равновесие дискретного отклика) следует искать не из решения транспортной задачи линейного программирования, а из решения энтропийно-регуляризованной транспортной задачи с коэффициентом регуляризации при энтропии, равным T (W. Sandholm «Population Games and Evolutionary Dynamics»).
В связи с вышенаписанным интересно заметить, что ряд специалистов в области численных методов оптимизации в числе одних из наиболее значимых достижений в области оптимизации за последние десять лет выделили наблюдение, экспериментально сделанное Марко Кутюри в 2013 году (Peyer G., Cuturi M. «Computational Optimal Transport»). Наблюдение состоит в том, что транспортные задачи линейного программирования (ЛП) намного эффективнее можно решать не с помощью соответствующих ЛП-солверов, а с помощью энтропийной регуляризации (как раз такой, как описано выше) и последующим применением к возникающей регуляризованной задаче алгоритма Синхорна (в транспортной литературе этот алгоритм использовался для расчета матрицы корреспонденций с 60-х годов прошлого века, и там этот метод получил название «метод балансировки» Брэгмана—Шелейховского; отличие от того, что предложил М. Кутюри, в том, что параметр T Кутюри выбирал сам должным образом (достаточно маленьким), а при расчете матрицы корреспонденций этот параметр отвечает за дисперсию шума в информации жителей города, и определяется этот параметр, как правило, из реальных данных путем калибровки (на него уже модель не строят)).
Неподвижная точка
Итак, выше мы ответили на вопрос о том, как формируется матрица корреспонденций и как эта матрица влияет на равновесное распределение потоков по путям. Казалось бы, тут можно ставить точку! На самом деле, правильно задавать еще и обратный вопрос: как равновесное распределение потоков по путям влияет на матрицу корреспонденций? В действительности тут получается порочный круг! Матрица корреспонденций, с одной стороны, определяет то, как распределяются потоки по путям, но, с другой стороны, чтобы посчитать эту матрицу, требуется знать матрицу затрат, которая формируется, исходя из равновесного распределения потоков по путям. Ведь чтобы знать, какие затраты будут на перемещение из одного района в другой, нужно знать, какая будет загрузка дороги. На практике этот гордиев узел разрубается следующим образом — ищется неподвижная точка. А именно, ищется такая пара (матрица корреспонденций и распределение потоков по путям), при которой выход одной модели дает вход другой, и наоборот. Собственно, современные многостадийные модели равновесного распределения потоков — это последовательная прогонка моделей Бекмана для блока распределения потоков по путям плюс энтропийная модель расчета матрицы корреспонденций, плюс модели расщепления пользователей (по использованию личного и общественного транспорта, по цели поездки и т. д. и т. п.; выше мы про это не писали, потому что идейно это не дает ничего нового относительно уже сказанного, впрочем, при желании посмотреть на простое объяснение модели расщепления передвижений на личном и общественном транспорте на том же самом модельном примере из двух районов можно рекомендовать модель М. Я. Блинкина, изложенную в приложении А книги Гасников А. В., Гасникова Е. В.). Прогонка (последовательные итерации) блоков модели осуществляется до тех пор, пока не будет стабилизации. На практике при должном выборе параметра T такую стабилизацию, как правило, можно наблюдать. Никаких теоретических объяснений для этого в таком варианте пока, насколько нам известно, не было.
***
Итак, в части 2 мы остановились на том, что для поиска равновесия в двухстадийной модели распределения транспортных потоков необходимо последовательно итерировать два блока, пока не будет наблюдаться стабилизация (выход на стационарный режим — неподвижную точку). То, что неподвижная точка существует,— известно, но вот то, что описанная процедура будет сходиться к этой неподвижной точке, пока не было строго обосновано.
В докторской диссертации А. В. Гасникова (руководитель — член-корреспондент РАН профессор А. А. Шананин, научный консультант — профессор Ю. Е. Нестерова) обоснование такой конструкции было дано. Точнее говоря, была предложена альтернативная схема, которая гарантированно сходится к нужной неподвижной точке. Причем сходится быстрее и на практике (во всяком случае, в тех экспериментах, которые удалось провести). Достаточно интересно, на наш взгляд, тут то, как именно эта схема родилась.
Складываем все вместе
Мы не случайно описали в первых двух частях два главных блока (модель распределения потоков по путям и модель расчета матрицы корреспонденций) в едином эволюционном ключе. Собственно, раньше на модель расчета матрицы корреспонденций так не смотрели. И та и другая модель на самом деле формализуются с математической точки зрения как равновесия в популяционных марковских динамиках «наилучших» ответов. В случае моделей Бекмана и стабильной динамики (последнюю модель в таком контексте, естественно, интерпретировать как частный случай модели Бекмана с вырожденными затратами: фиксированными до пропускной способности и бесконечными после) это и правда динамика наилучших действий (реакций) водителей на информацию о распределении водителей по путям с прошлой итерации (вчерашнего дня), а вот в случае динамики по расчету матрицы корреспонденций под «наилучшей» следует понимать так называемую логит-динамику, отражающую отмеченную в части 2 недоинформированность водителей и возможность принять в том числе не наилучшее решение, исходя из того, что было на прошлой итерации. Что тут понимается под равновесием? Динамики стохастические. Со временем они выходят на стационарное распределение (эргодическая теорема), а с ростом числа агентов (водителей) эти стационарные распределения концентрируются (явление концентрации меры, а в более классической терминологии это также можно называть центральной предельной теоремой) около определенных макросостояний. Собственно, отмеченные макросостояния и будут равновесия. А функции, которые необходимо было минимизировать для поиска этих равновесий, с одной стороны, будут функциями, характеризующими концентрацию стационарных мер этих динамик (такие функции называют функционалы Санова), но в то же самое время эти функции будут в среднем монотонно убывать на траекториях этих динамик (специалисты по дифференциальным уравнениям называют такие функции функциями Ляпунова). Таким образом, получается, что те «вариационные принципы», которые лежат в основе описанных выше моделей, имеют вполне естественную природу. С учетом приведенной здесь интерпретации целевых функционалов в описанных моделях интересно заметить, что аналогичным образом в статистической физике смотрят на функционал энтропии термодинамической системы (Больцман, Гибсс).
Собственно, для чего все это мы сейчас привели? Для того чтобы пояснить главную идею, как можно получить эквивалентный способ поиска неподвижной точки в многостадийной транспортной модели, не прибегая к методу простой итерации. А именно, поскольку каждая из описанных моделей-блоков имеет такую эволюционную природу и эти модели «живут» в разном масштабе времени, может быть, можно рассмотреть эти динамики не по отдельности, а вместе (наложенными друг на друга, как в реальной жизни)? Даст ли это что-то?
Ну если мы верим в то, что достаточно неплохо описали реальность, то, наверное, мы вправе надеяться, что это что-то даст. Так оно и есть на самом деле. Оказывается, что в такой уже более сложной динамике с использованием теоремы Тихонова о разделении времен (точнее, стохастического варианта этой теоремы; в литературе также можно встретить близкие концепции, среди которых отметим принцип подчинения Хакена) также можно получить все то, что мы делали выше для каждого из блоков в отдельности. Таким образом, получается целевой функционал (довольно сложной минмакс структуры; мы здесь не будем на этом останавливаться подробно, детали см. в книге Гасников А. В., Гасникова Е. В.), минимизация которого и дает искомое равновесие (неподвижную точку). Но в отличие от предыдущего подхода за счет того, что этот функционал получается выпуклым, можно строго обосновать интересующую нас сходимость к равновесию и изучать вопросы его единственности. Но самое главное тут то, что, сводя задачу поиска равновесия к задаче минимизации выпуклой функции, мы гарантированно можем находить настоящее равновесие с полным теоретическим контролем сложности этой задачи (см., например, Гасников А. В. «Современные численные методы оптимизации. Универсальный метод градиентного спуска»). Отметим также, что в отличие от упомянутого выше сюжета, связанного с энтропийной регуляризацией, в котором «природа» подсказала то, как стоит численно решать задачу, тут имеет место обратная ситуация. «Природа», ну а точнее, наше понимание ее, устроена тут так, что динамика модели расчета матрицы корреспонденций происходит в медленном времени (годы), и под нее подстраивается динамика распределения потоков по путям (дни—недели). Таким образом, можно было бы ожидать, что и на практике следовало бы делать несколько итераций метода, который ищет равновесное распределение потоков по путям (решает соответствующую задачу), а потом одну итерацию по модели расчета матрицы корреспонденций (там решается уже другая задача оптимизации) и т. д. На самом деле, удалось строго доказать, что описанный выше подход полностью доминируется в вычислительном плане обратным подходом, когда на одну итерацию модели равновесного распределения потоков по путям приходятся несколько итераций по модели расчета матрицы корреспонденций.
Практическое применение
Все, что выше описано, было численно проверено на ряде американских городов (данные по которым удалось найти в свободном доступе). Мы думаем, что настал подходящий момент попробовать все это применить в должном объеме к ряду российских городов. Наши исследования на регулярной основе поддерживаются различными научными грантами. В частности, в данный момент мы работаем по гранту РФФИ 18–29–03071 мк (руководитель — профессор Е. А. Нурминский, известный специалист в области транспортного моделирования в России). Однако хотелось бы отметить проблему нехватки данных для моделирования. Надеемся, что данные заметки обратят внимание не только на научные вопросы, связанные с тем, как моделировать и считать, но и на то, где и как брать для этого данные. Ведь чем системнее будут данные, тем надежнее и точнее могут быть расчеты и польза от них.
Александр Гасников, д.ф.-м.н., доцент МФТИ, в.н.с. ИППИ РАН, профессор ВШЭ; Павел Двуреченский, к.ф.-м.н., с.н.с. ИППИ РАН